前瞻与回顾:反射式
记忆管理
当 AI 需要像人一样"记住"——Google Cloud AI Research 提出 RMM 框架,用前瞻反射组织记忆、回顾反射优化检索,让对话代理在跨会话场景中真正做到"个性化记忆"。
引言:为什么对话代理需要"反射式"记忆
大语言模型(LLM)在开放式对话中展示了卓越的能力,但它们固有的无状态性给维持连贯、个性化的长期对话带来了重大挑战。这种局限性在客户服务、虚拟助手和教育平台等需要持续个性化的真实应用中尤为突出。
如图 1 所示,一个个性化的医疗助手需要不仅理解当前对话的上下文,还要回忆用户在过去会话中提到的过敏史和症状——这正是现有系统力不从心的地方。

为了解决 LLM 的上下文窗口限制,外部记忆机制应运而生,使 LLM 能够保持对话的连续性。但现有方法面临两个关键挑战:
挑战一:固定粒度导致记忆碎片化。现有系统在预定义的粒度(如轮次、会话或时间间隔)上组织信息,这可能与对话的自然语义结构不一致。例如,一个关于"旅行计划"的话题可能跨越多个轮次和会话,但被固定粒度切割成碎片。
挑战二:固定检索器无法适应多样化场景。这些系统依赖于固定的检索器,难以适应不同对话领域和个人用户的交互模式。训练个性化检索器所需的标注数据成本高昂,构成了规模化的重大障碍。
为此,论文提出了反射式记忆管理(Reflective Memory Management, RMM),一种融合前向和后向反射的新型长期对话记忆机制:
- 前瞻反射(Prospective Reflection):按话题动态总结交互历史,跨越话语、轮次和会话的边界,形成个性化记忆库
- 回顾反射(Retrospective Reflection):利用 LLM 的引用信号,通过在线强化学习迭代优化检索过程
实验表明,RMM 在 MSC 和 LongMemEval 两个基准上一致超越所有基线。例如,在 LongMemEval 上比无记忆基线提高了超过 10% 的准确率。
2025 年是 Agent 记忆系统的军备竞赛年。MemoryBank、LD-Agent、Mem0、Theanine、A-mem 等框架密集发布。RMM 的独特之处在于——它不只是"怎么存记忆",而是同时解决了"怎么组织记忆"和"怎么学会更好地取记忆"。这是一个存取双优化的框架。
"固定粒度"问题的本质是人为边界与语义边界的错位——就像你把一本书按每 10 页切一刀来做笔记,切断点恰好在一个论证的中间。"固定检索器"问题的本质是一个通用模型无法理解个人偏好——同一个查询"我喜欢什么",对不同用户应该检索完全不同的记忆片段。
第一作者 Zhen Tan 来自 ASU,但实习在 Google Cloud AI Research。通讯作者包括 Jun Yan 和 Tomas Pfister(Google)。这意味着 RMM 很可能会被整合到 Google Cloud 的 Vertex AI Agent Builder 或类似产品中。
有趣的是,RMM 解决的"话题级记忆组织"问题,在 Claude Code 的记忆系统中是用完全不同的方式处理的——Claude 用的是文件级分类(user / feedback / project / reference),而 RMM 用的是动态话题聚类。前者适合异步工具场景,后者适合实时对话场景。两种设计哲学反映了不同的使用模态。
当 AI 能够"记住"你的所有过去——你的过敏史、你的喜好、你的情绪模式——它是在成为更好的助手,还是在构建一个你无法控制的数字画像?长期记忆的便利性和隐私侵蚀之间,边界在哪里?
问题与框架:RMM 的整体设计
问题定义
论文考虑的是多会话对话(multi-session conversational)场景:一个代理与用户跨越多个独立会话进行交互。每个"会话"(session)代表一段独立的交互期,可能因用户不活跃、显式结束或新话题开始而界定。会话内部由一系列"轮次"(turn)组成,每个轮次包含用户查询和代理回复。
代理配备了一个外部记忆,作为存储过去会话信息的唯一仓库。代理的目标是生成既与当前上下文相关、又融合了过往个人信息的回复。
这带来了两个核心挑战:(1) 代理必须主动识别并存储每个会话中的关键信息,预判未来的检索需求;(2) 代理必须精确检索相关的过去信息,因为引入不相关的上下文会分散 LLM 的注意力并降低回复质量。
框架概览
RMM 框架包含四个核心组件:
- 记忆库(Memory Bank):以"话题摘要 + 原始对话片段"配对的形式存储对话历史,话题摘要作为检索键
- 检索器(Retriever):基于用户查询从记忆库中获取相关记忆条目
- 重排器(Reranker):轻量级模块,对检索器返回的结果进行二次排序,筛选最相关的 Top-M 条记忆
- LLM:综合当前对话和检索到的记忆,生成个性化回复,同时输出引用信号用于优化重排器

完整工作流如算法 1 所示:每轮交互中,检索器从记忆库获取 Top-K 条记忆,重排器筛选出 Top-M 条最相关的,LLM 基于这些记忆生成回复。关键创新在于,LLM 会同时输出对每条被检索记忆的引用评分(+1 有用 / -1 无用),这些信号被用作强化学习的奖励来优化重排器。当一个会话结束时,系统提取该会话中的话题级记忆并更新记忆库。
RMM 没有试图做一个"万能的端到端记忆系统",而是把记忆管理拆成了四个独立的、各司其职的组件。这是一个关注点分离(separation of concerns)的经典设计——检索器负责召回,重排器负责精排,LLM 负责生成和评价。这种设计的好处是:每个组件可以独立升级,而不需要重新训练整个系统。
用话题摘要(而非原始对话文本)作为检索键,是一个被低估的设计决策。原始对话充满了口语化的杂音——"嗯"、"那个"、"你知道吗"——这些噪声会严重干扰向量检索的精度。摘要相当于一个语义去噪层,把"用户上周三在讨论想去日本旅行的事情"压缩成"用户有日本旅行计划"。
用 LLM 的引用行为作为 RL 奖励信号,避免了昂贵的人工标注。但这里有一个自证循环的风险:LLM 倾向于引用它"理解得最好"的记忆,而不一定是"对用户最有用"的记忆。如果 LLM 对某类信息有系统性偏见(比如更容易引用事实型记忆而忽略情感型记忆),重排器就会被训练成放大这种偏见。
论文选择不微调检索器本身,而是加了一个轻量重排器。原因很务实:微调检索器需要大量标注数据且容易灾难性遗忘(catastrophic forgetting),而重排器只是一个小型 MLP,训练成本几乎可以忽略。这是一个"实用主义 > 完美主义"的工程决策。
RMM 用 LLM 自己的引用行为来训练检索系统——本质上是让"出题者"同时当"阅卷老师"。如果 LLM 有系统性的注意力偏见(比如更容易记住负面情感、忽略积极细节),这个系统会不会把一个"有偏见的回忆者"固化成一个"有偏见的记忆系统"?
前瞻反射:基于话题的记忆组织
传统记忆系统通常依赖固定边界(如会话分隔符或轮次界限)来组织对话历史。但这些预定义边界可能与对话的内在语义结构不一致,导致关键信息被分散到多个记忆条目中,阻碍有效检索。
为解决这个问题,论文引入了前瞻反射(Prospective Reflection),一种基于连贯话题的记忆组织机制。这里的"话题"指的是一个语义连贯的讨论单元,可以跨越一个或多个轮次。
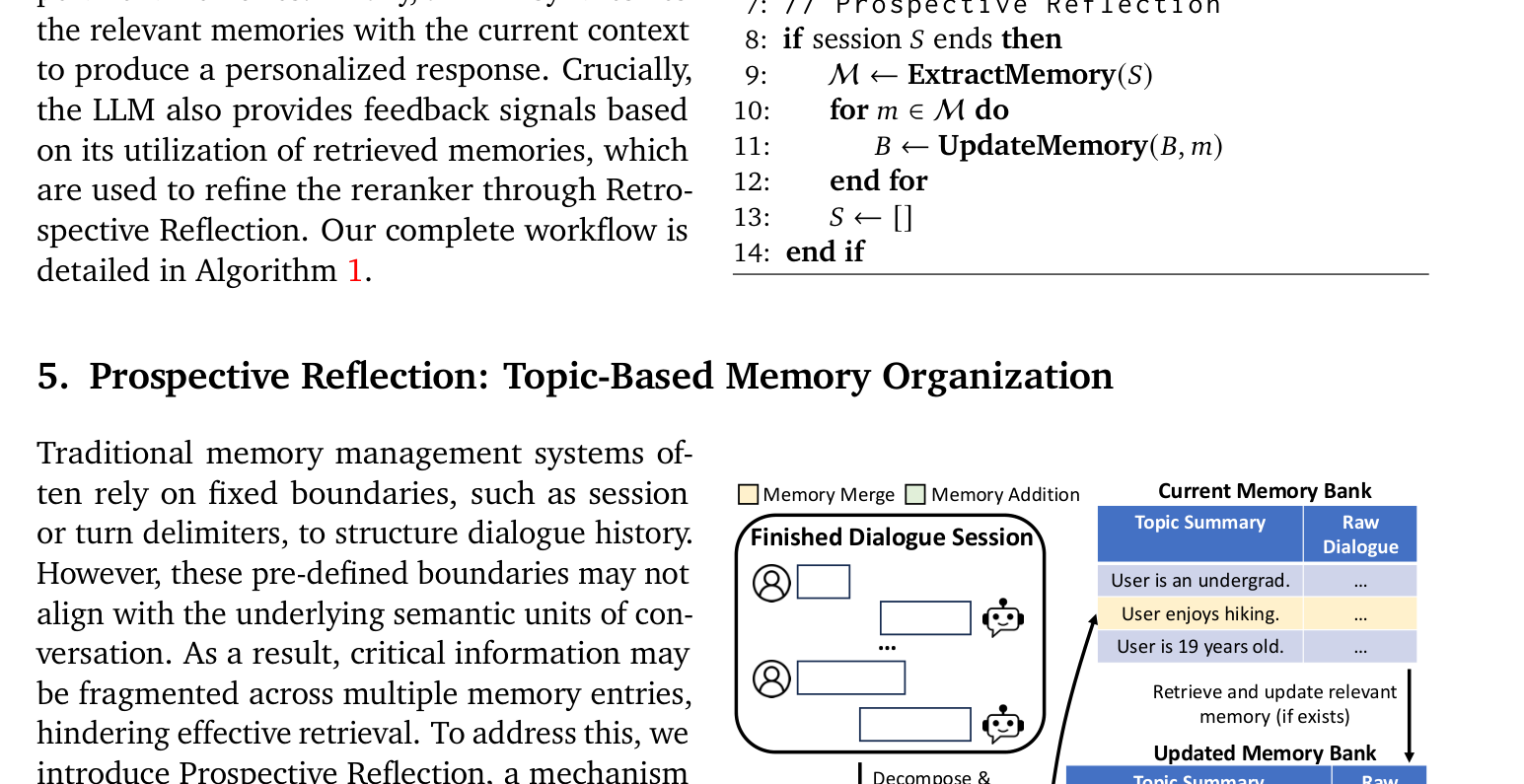
如图 2 所示,前瞻反射在每个会话结束时执行,包含两个关键步骤:
步骤一:记忆提取。使用 LLM 从会话中提取对话片段及其对应的话题摘要。每个提取的记忆条目是一个"话题摘要 + 原始对话片段"的配对。话题的粒度从细粒度的用户意图(如询问素食食谱)到更广泛的主题(如旅行规划)不等。
步骤二:记忆更新。将提取的记忆整合到记忆库中。具体做法是:对每条新提取的记忆,检索记忆库中语义最相似的 Top-K 条现有记忆,然后让 LLM 判断是合并(当新记忆是对已有话题的更新时)还是添加(当新记忆涉及一个全新话题时)。
通过这种方式,记忆库维护着一个连贯、合并的对话历史表示,围绕有意义的话题结构组织,而非被任意的会话边界切割。
前瞻反射看似简单,但它的核心难点被论文轻描淡写了:如何判断一条新记忆应该"合并"还是"添加"?这个决策完全依赖 LLM 的语义判断能力。如果 LLM 误判——把两个不同话题的记忆合并了、或者把同一话题的更新当作新话题添加了——错误会永久累积在记忆库中,无法自我纠正。论文没有讨论记忆纠错机制。
前瞻反射选择在会话结束后才提取记忆,而非每轮实时提取。这是一个深思熟虑的设计:实时提取会导致频繁的记忆库写入,增加延迟;而批量提取可以在完整对话的上下文中做出更准确的话题分解。但代价是——如果系统在会话中间崩溃,整个会话的记忆都会丢失。在生产环境中,这是一个不可忽视的可靠性风险。
有趣的是,我们自己的 deploy-guide 系统也面临类似的"记忆粒度"问题。rules.md 按"规则"组织(类似话题级),raw/ 日志按"部署事件"组织(类似会话级)。Phase 9 的"自动反射"本质上就是 deploy-guide 版的 Prospective Reflection——从 raw 日志中提取经验教训,合并到 rules.md 中。
前瞻反射用 LLM 来决定哪些记忆应该合并——但 LLM 的"语义理解"和人类的"觉得相关"之间,真的是同一回事吗?一个人类用户可能觉得"我爱吃寿司"和"我想去日本旅行"高度相关,但向量空间中它们可能相距甚远。我们是在用机器的关联方式来替代人的关联方式——这种替代的损失,谁在计量?
回顾反射:用 RL 优化记忆检索
6.1 重排器设计
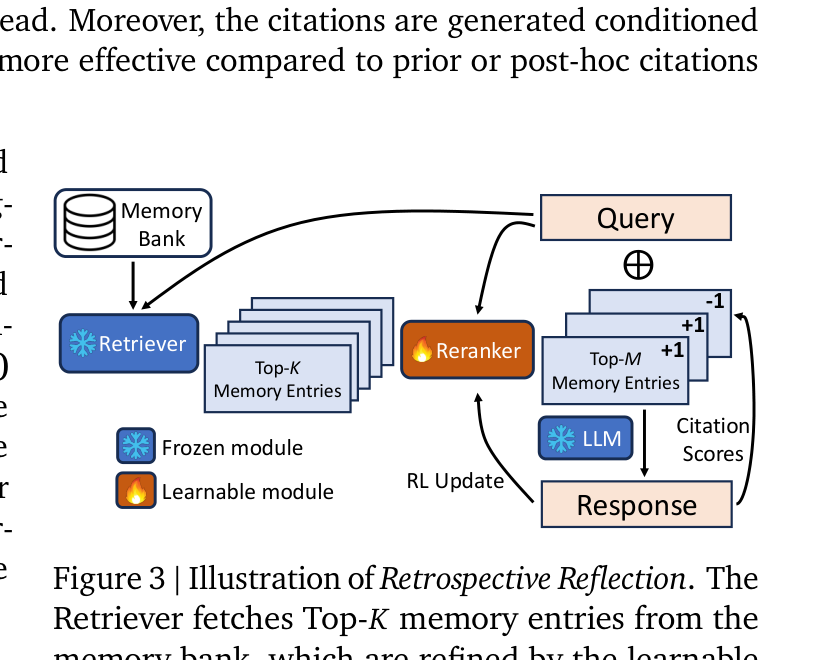
现成的检索器虽然能识别语义相关的记忆,但在不同对话领域和用户交互模式中性能会下降。与其对检索器进行昂贵的全量微调,RMM 引入了一个轻量级重排器来精炼检索结果。
具体而言,重排器处理检索器返回的 Top-K 条记忆嵌入,通过以下步骤选出 Top-M 条最相关的候选:
嵌入适配。查询嵌入 q 和记忆嵌入 mi 通过带残差连接的线性层进行适配:q' = q + Wqq,m'i = mi + Wmmi。
Gumbel 采样。计算适配后的查询与记忆嵌入的点积作为相关性分数,然后使用 Gumbel Trick 进行随机采样。温度参数 τ 控制分布的锐度——低 τ 趋向确定性采样,高 τ 鼓励探索。
6.2 LLM 引用作为奖励信号
论文巧妙地利用 LLM 生成器本身的能力来提供检索优化的反馈。给定用户查询、当前会话上下文和检索到的记忆,LLM 被提示同时生成回复和对每条记忆的引用评分。
奖励机制:如果生成器在回复中引用了某条记忆,该记忆获得 +1(有用)的奖励;否则获得 -1(无用)的奖励。这种二元奖励直接反映了 LLM 对检索记忆的实际利用情况。
6.3 重排器更新
重排器使用 REINFORCE 算法进行优化,策略梯度公式为:Δφ = η · (R - b) · ∇φ log P(MM|q, MK; φ),其中 R 是奖励(+1 或 -1),b 是基线值(设为 0.5),φ 是重排器参数。
这种设计的关键优势是:重排器可以在线学习,随着对话的进行持续适配每个用户的交互模式,而不需要任何预先收集的标注数据。
论文选择了最简单的策略梯度算法 REINFORCE,而非 PPO、A2C 等更先进的 RL 算法。这不是偷懒——这是奖励信号太稀疏的结果。每轮对话只有 M 条记忆的引用/非引用二元信号,这种低信息密度的反馈下,复杂的 RL 算法反而容易过拟合。REINFORCE 的简单性恰好匹配了信号的稀疏性。这是一个"问题决定方法"的典型案例。
Gumbel 采样不只是一个技术细节,它解决了 RL 中探索-利用困境的核心问题。如果重排器只选"最可能有用的"记忆(利用),它永远不会发现那些"看起来不太相关但实际上很有用"的记忆(探索)。Gumbel 噪声引入了受控的随机性,让系统有机会"试错"——这和人类"偶然翻到旧笔记发现有用信息"的体验异曲同工。
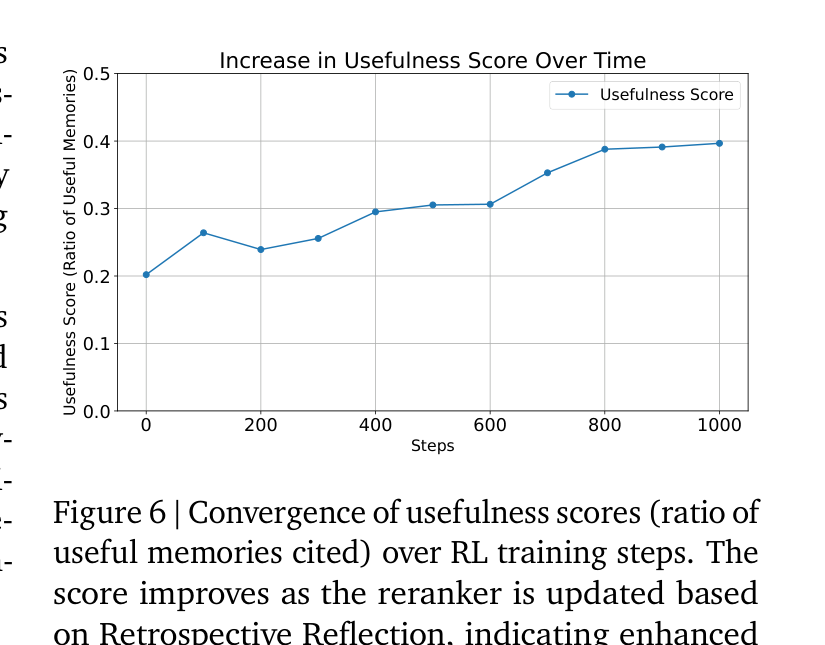
论文在 Table 3 中验证了引用评分的质量:精确率 87.6%,召回率 85.8%,F1 86.7%。这个数字看起来不错,但意味着大约每 7 次引用判断就有 1 次是错的。在 RL 中,10-15% 的噪声奖励会导致策略学习的不稳定。论文没有讨论这种奖励噪声对长期收敛的影响——1000 步之后收敛到 0.4 的有用记忆比例,这个天花板是否就是奖励噪声导致的?
重排器只是一个带残差连接的 MLP——参数量极小,训练几乎不增加延迟。这种"在大模型旁边放一个小模型做适配"的模式,和 LoRA 的思路一脉相承。核心理念是:不要动大象,给大象配一个灵活的小助手。
重排器通过 RL 学会了"哪些记忆对 LLM 生成回复有用"——但"对 LLM 有用"和"对用户有用"是同一件事吗?如果 LLM 倾向于引用事实性记忆("用户 19 岁")而忽略情感性记忆("用户最近很焦虑"),重排器会被训练成一个"只记得数据、忘记感受"的系统。个性化对话中最重要的那一层——共情——恰恰是最难被引用信号捕捉的。
实验设计与核心结果
实验配置
论文使用 Gemini-1.5-Flash 作为默认生成器,并额外评估了 Gemini-1.5-Pro。检索器测试了三种:Contriever(默认)、Stella 和 GTE。评估在两个公开基准上进行:
- MSC(Multi-Session Chat):评估生成回复与人工标注 ground truth 的匹配度,使用 METEOR 和 BERTScore
- LongMemEval:评估从对话历史中检索相关信息的能力,使用 Recall@K 和 LLM 判断的准确率
核心结果
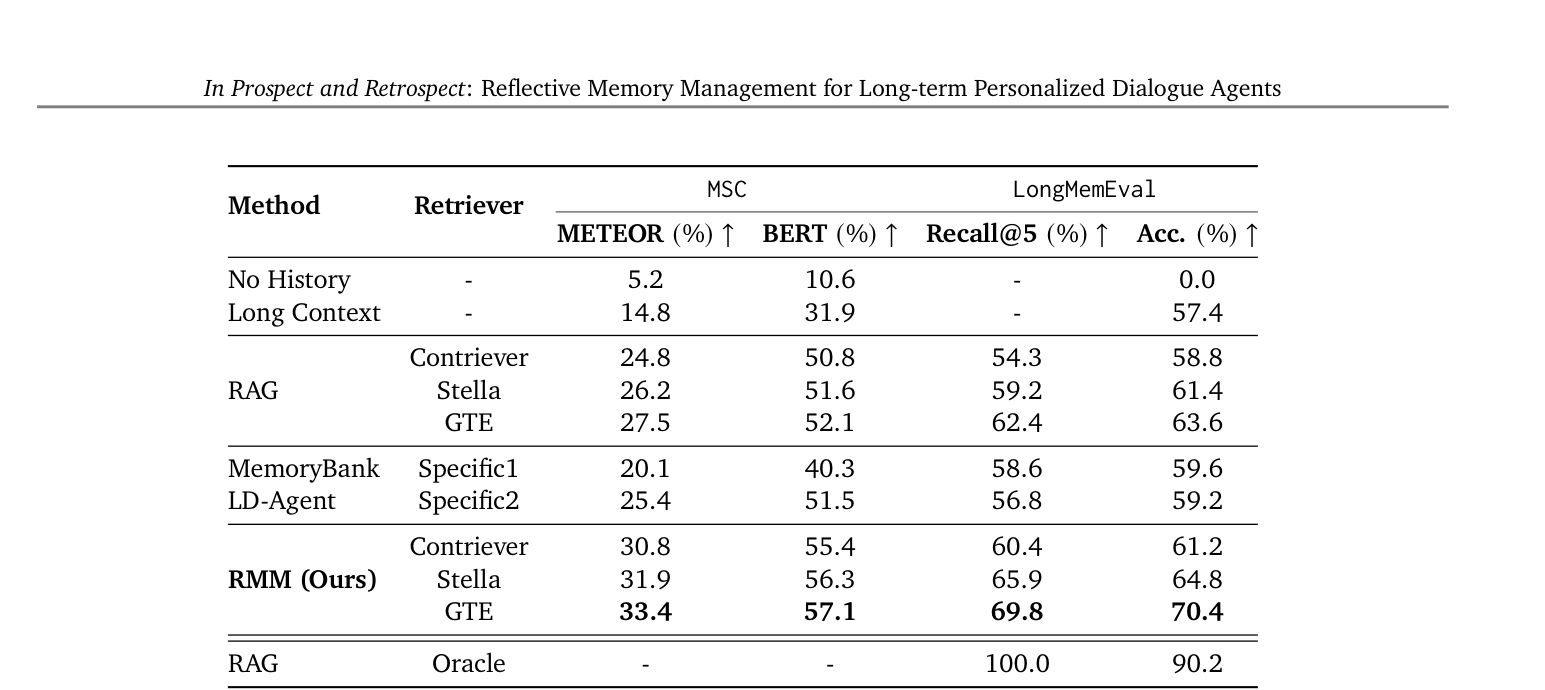
历史信息至关重要。无历史基线在 MSC 上仅获得 5.2% METEOR,在 LongMemEval 上准确率为 0.0%——长期记忆不是锦上添花,而是生死攸关。
长上下文不够用。直接塞入所有历史的长上下文方式表现低迷——噪声上下文严重干扰 LLM 判断。
RMM 一致领先。即使使用较弱的 Contriever 检索器,RMM 仍保持竞争力,展现鲁棒性。
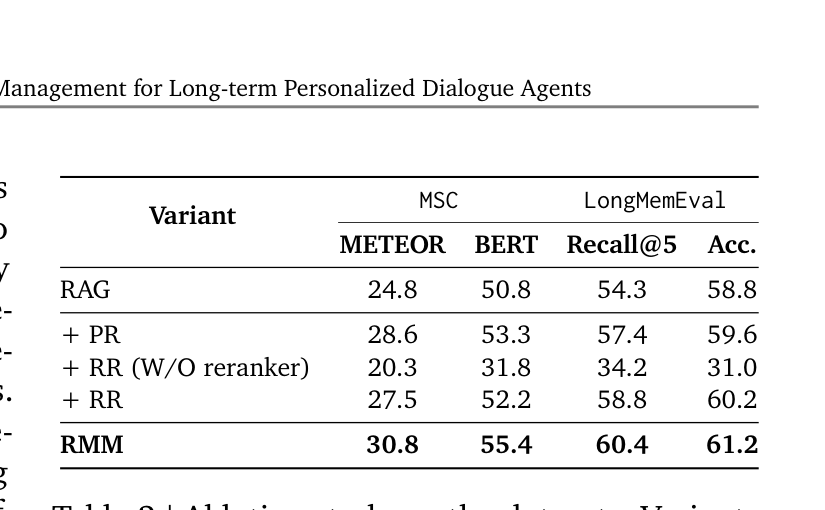
消融实验


LongMemEval 上无历史基线的 0.0% 准确率是全文最惊人的数字。它不只是说"没有记忆表现差"——它在说没有记忆就完全无法完成任务。LongMemEval 的问题都是必须依赖历史信息才能回答的类型。这个 0% 本身就是对"LLM 不需要外部记忆"论调的最强反驳。
更弱的 Gemini-1.5-Flash 在 RMM 中反而比 Pro 更好。论文归因于 Pro 更强的隐私保护对齐——它被训练得更不愿回答涉及个人信息的问题。这揭示了一个深层矛盾:模型的"安全性"和"个性化"之间存在根本张力。越安全的模型越不愿利用用户个人信息,但个性化对话的核心就是利用个人信息。
单独加 RR 但不带重排器(直接微调检索器),LongMemEval Recall@5 从 54.3% 暴跌到 34.2%。这证实了灾难性遗忘在小数据 RL 场景中的严重性。论文由此引入重排器作为"安全网"。核心洞察:与其改造一个复杂系统,不如在上层加一个可学习的适配层——和 LoRA 的思路一脉相承。
论文没有与 2025 年同期发布的 Mem0、A-mem、Zep 等框架做对比。MemoryBank 和 LD-Agent 是 2024 年的工作,作为基线偏弱。RMM 的优势在更强基线下是否仍然成立?这是一个开放问题。
RMM 在 MSC 上的最佳 METEOR 是 33.4%——生成回复和人类标注之间只有三分之一的词汇重叠。我们在用一个"只有 33% 相似度"的系统来做个性化对话——这到底是"AI 记忆的巨大进步",还是"我们对个性化对话的期望太低了"?
深度分析与讨论
粒度分析
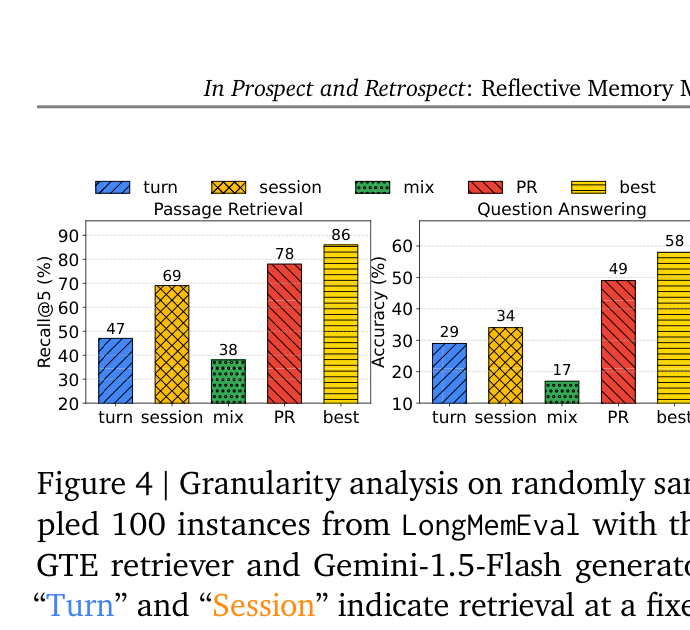
实验证明前瞻反射的灵活粒度优于所有固定方案。会话级因上下文更丰富优于轮次级,但混合两种反而因噪声增加而下降。前瞻反射的话题级粒度接近按实例选择最佳粒度的 oracle 上界。
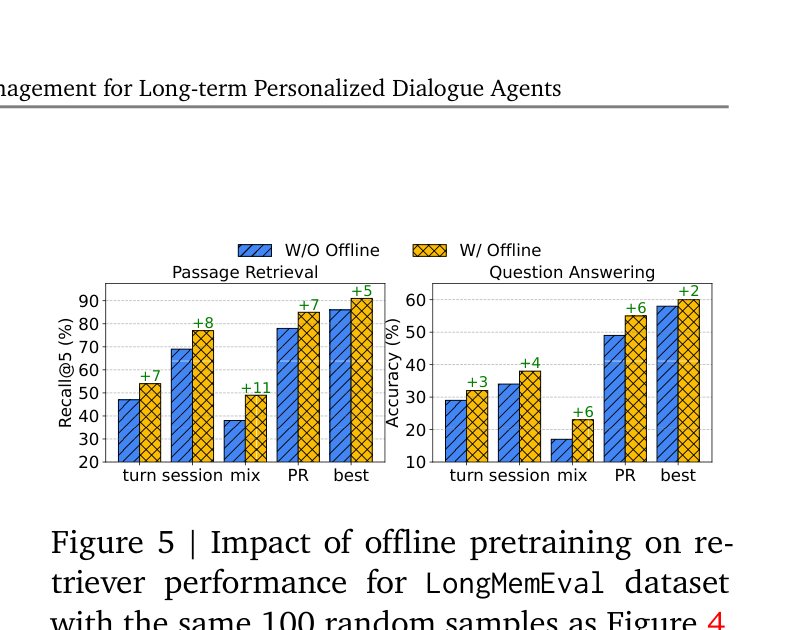
离线预训练
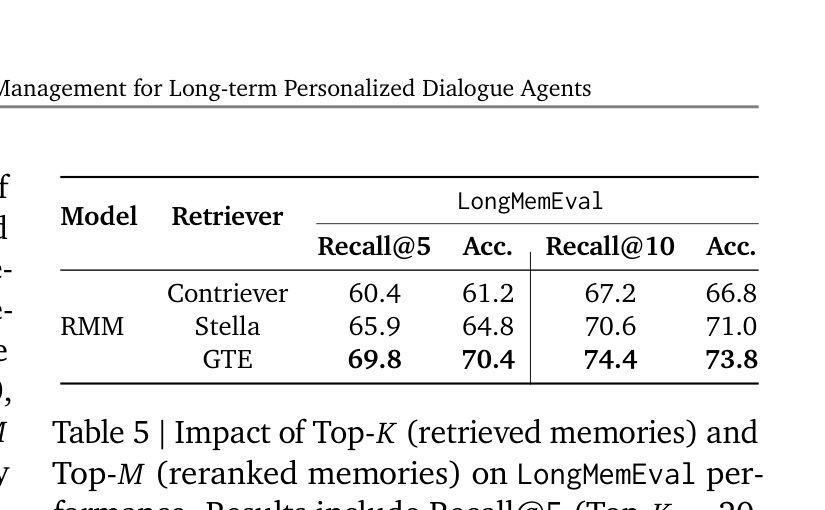
Top-K 与 Top-M 的影响
RL 训练收敛
局限性
论文坦诚承认三个主要局限:(1) RL 记忆重排在大规模或实时场景中计算成本高昂;(2) 框架仅处理文本对话,不支持多模态;(3) 记忆更新机制在长期动态演变的用户交互中可能需要进一步优化。
结论
RMM 通过整合前瞻反射(话题级记忆组织)和回顾反射(基于 RL 的动态检索优化),在两个基准数据集上全面超越现有方法。论文明确指出了固定粒度和静态检索器的局限性,为长期对话记忆建模指明了未来方向。
RL 收敛到约 40% 有用记忆比例后就停滞。这意味着即使在最优状态下,检索到的 5 条记忆中仍有 3 条是无用的。根源可能有三:(1) 引用评分 ~14% 错误率引入奖励噪声;(2) 检索器的召回上限——重排器只能从 Top-K 中选;(3) "有用"定义太严格——有些记忆虽未被直接引用,但可能影响了回复语气。
RMM 的记忆库是一个只增不删的系统——前瞻反射只做"合并"和"添加",没有"遗忘"和"淘汰"。在真实长期对话中(数月、数年),记忆库会无限膨胀,检索效率持续下降。MemoryBank 至少用了艾宾浩斯遗忘曲线来模拟自然遗忘,而 RMM 完全忽略了这个问题。一个永不遗忘的系统不是好的记忆系统——人类记忆的强大恰恰在于善于遗忘不重要的信息。
附录透露实验在 16 块 NVIDIA A100 GPU 上进行。对于宣称"轻量级"的重排器来说,这个规模令人意外。虽然 A100 主要用于 LLM 推理,但这暴露了实用性问题:每个用户都需要独立的 RL 训练循环吗?如果是,成本根本无法规模化。
论文提到要做多模态和隐私保护。但最有价值的延伸是跨用户知识迁移——如果用户 A 的重排器学到了"健康类记忆在医疗对话中优先级高",这个知识能否迁移给新用户 B?这将解决冷启动问题并大幅降低 per-user RL 成本。
RMM 证明了 AI 可以学会更好地"记忆"——但它学的是记忆的机械层面(存什么、怎么存、怎么取),而非记忆的人性层面(什么值得珍藏、什么该被温柔地忘记、什么在特定情境下会被触发)。当我们把记忆简化为"向量检索 + 强化学习",我们是否正在创造一种新型的"技术性孤独"——一个能准确引用你过去说的每一句话、却从未真正"理解"你的系统?
参考文献
本文引用了 40+ 篇文献,涵盖长期对话系统、个性化代理、记忆管理、强化学习等领域。核心参考包括:Xu et al. (2022) MSC 数据集、Wu et al. (2025) LongMemEval 基准、Zhong et al. (2024) MemoryBank、Li et al. (2025) LD-Agent、Izacard et al. (2022) Contriever 检索器等。完整参考文献列表请查阅 arXiv 原文。
附录
附录包含四部分:A. 实现与训练细节(重排器 MLP 架构、REINFORCE 超参数、16x A100 GPU 硬件配置);B. 数据集描述(MSC 多会话对话数据集、LongMemEval 长期记忆评估基准);C. 案例研究(RMM 如何在实际对话中检索和利用跨会话记忆);D. Prompt 模板(记忆提取、记忆更新、回复生成与引用评分的完整 prompt)。详见 arXiv 原文 第 18-29 页。